- Zirui Gong1
- Yanjun Zhang2
- Leo Yu Zhang1
- Zhaoxi Zhang2,1
- Yong Xiang3
- Shirui Pan1
- 1Griffith University
- 2University of Technology Sydney
- 3Deakin University

Real-word Applications of Federated Learning (FL)
👁️ A Quick Glance
📚 Problem Statement
-
Federated Rank Learning (FRL) is a promising FL training framework, designed to address communication bottlenecks and improve system robustness against poisoning attacks.
How it works?
It expands the LTH hypothesis to the federated learning framework, where clients work collaboratively to select a subnetwork that maintains high performance as the original fully trained supernetwork. Specifically, FRL consists of the following three steps:
Server Initialization:
In the first round, the server chooses a seed to generate random weights \( \theta^w \) and scores \( \theta^s \) for each edge in the global supernetwork; (Note that in the subsequent training, only the scores \( \theta^s \) are updated.) Then, it sorts the scores \( \theta^s \) in ascending order to get the corresponding global ranking \( R_g \), where each value represents edge ID and the index indicates the edge's reputation (with higher indices denoting greater importance). Finally, the server sends the global ranking \( R_g \) to the selected \( U \) clients.
Client Training:
Upon receiving the weights \( \theta^w \) and scores \( \theta^s \), the client uses the edge-popup (EP) algorithm to update the score \( \theta^s \) for each edge, such that if having an edge \( e \) selected for the subnetwork reduces the training loss (e.g., cross-entropy loss), the score of edge \( e \) increases. Then, clients sort the updated scores and send the updated rankings back to the server for aggregation.
Server Aggregation:
The server receives the local updates \( R_u \) for \( u \in [1, U] \) and performs majority voting (MV) to get the aggregated global ranking. Specifically, the server first aligns the reputation scores across users by sorting them based on edge IDs. After alignment, the server performs a dimension-wise summation of these sorted reputation scores to compute the aggregated reputation for each edge. Then, the server sorts these aggregated reputation scores in ascending order to generate the final ranking of edge IDs. For instance, if a client's ranking is \( R_u = [3, 4, 5, 1, 6, 2] \), where edge \( e_3 \) is the least important edge (first index) and \( e_2 \) is the most important edge (last index), the server assigns reputation scores \( I_u = [4, 6, 1, 2, 3, 5] \) based on their indices in \( R_u \). The server then sums these scores across all users to obtain the aggregated reputation, i.e., \( W = \sum_{u=1}^{U} I_u \). Finally, the server sorts the aggregated reputation in ascending order and maps them to their corresponding edge IDs, producing the global ranking \( R_g \).
This global ranking can then be transformed into a supermask \( \mathbf{M} \) (a binary mask of 1s and 0s), which is applied to the random neural network (the supernetwork) to generate the final subnetwork.
In summary, the objective of FRL is to find a global ranking \( R_g \), such that the resulting subnetwork \( \theta^w \odot \mathbf{M} \) minimizes the average loss of all clients. Formally, we have:
\[ \begin{aligned} & \min_{R_g} F(\theta^w, R_g) = \min_{R_g} \sum_{u=1}^U \lambda_u \mathcal{L}_u(\theta^w \odot \mathbf{M}), \\ & \text{s.t.} \quad \mathbf{M}[R_g[i]] = \begin{cases} 0, & \text{if } i < t, \\ 1, & \text{otherwise}, \end{cases} \end{aligned} \] where: \( U \) denotes the number of clients selected for the current iteration, \( \theta^w \) represents the global weights, \( \mathcal{L}_u \) and \( \lambda_u \) represent the loss function and the weight for the \( u^{\text{th}} \) client, respectively, \( t = \left\lfloor n \left(1 - \frac{k}{100}\right) \right\rfloor \) is the index of the selection boundary for the subnetwork, \( k \) indicates the sparsity of the subnetwork (i.e., top \( k\% \) of edges are selected), and \( n \) is the number of edges in each layer.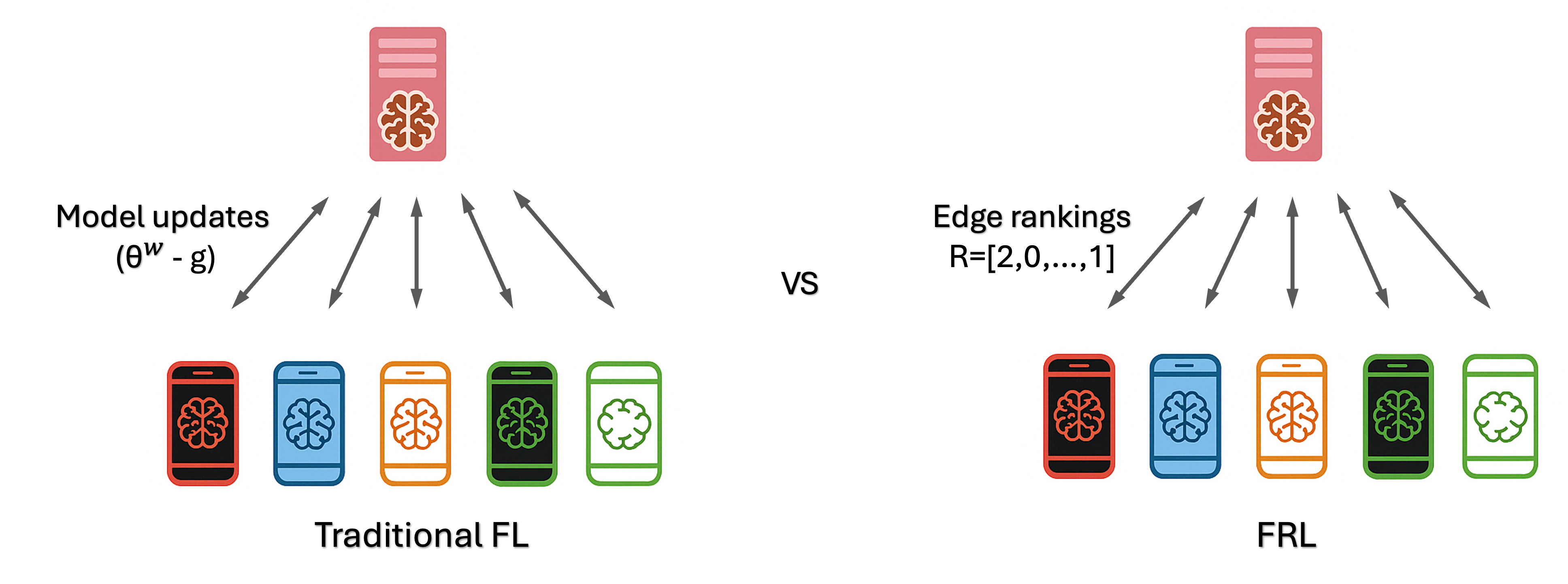 Why is it robust against client-side poisoning attacks? 1) Discrete update narrows the potential space for malicious updates from an infinite range to n!, effectively bounding the adversary’s damage within a defined budget. 2) Discrete updates also make existing optimization-based model poisoning attacks inapplicable directly. 3) It utilizes majority voting to determine the global ranking. This approach prevents malicious clients from making significant adversarial modifications to the global model, as each client only has a single vote.
Why is it robust against client-side poisoning attacks? 1) Discrete update narrows the potential space for malicious updates from an infinite range to n!, effectively bounding the adversary’s damage within a defined budget. 2) Discrete updates also make existing optimization-based model poisoning attacks inapplicable directly. 3) It utilizes majority voting to determine the global ranking. This approach prevents malicious clients from making significant adversarial modifications to the global model, as each client only has a single vote.
⚙️ Methods
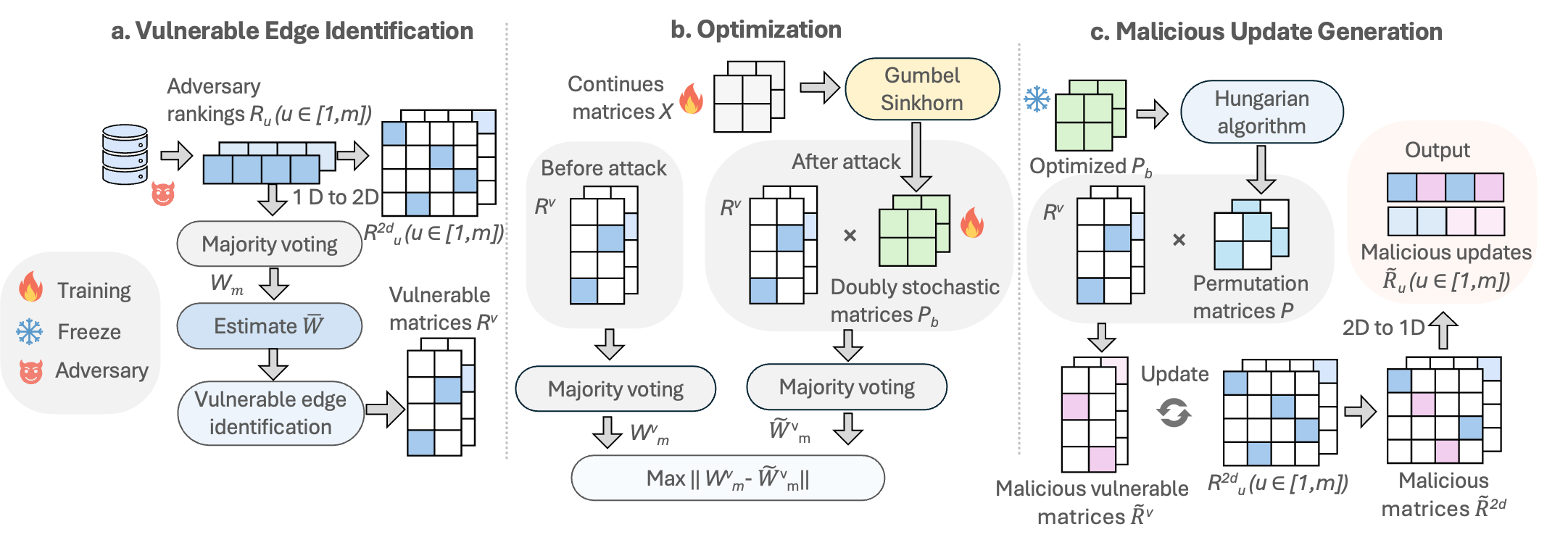
Our VEM aims to manipulate malicious updates such that the aggregated global model deviates significantly from their original ones at each training round, thus negatively affecting the global model performance. To effectively achieve this goal and make the FRL framework tackleable, we first provide a formalization of FRL. Specifically, we expand the 1D ranking into a 2D matrix to reduce the non-differentiable operations involved in the original algorithm.
Based on the formalization, our attack unfolds in three main stages: vulnerable edge identification, optimization, and malicious update generation. In the first stage, the adversary aims to identify vulnerable edges within each layer. To achieve this, it uses the rankings generated from its own datasets and simulates the majority voting process locally. After getting the aggregated ranking, it incorporates the global ranking from the previous round to estimate vulnerable edges. Once identified, the adversary extracts the ranking of those vulnerable edges to form vulnerable matrices.
In the optimization stage, the adversary aims to target those vulnerable edges and form the optimization function such that the global model's reputation of those vulnerable edges deviates significantly from their original values. To solve the optimization function, we use the Gumbel-Sinkhorn method to convert a discrete problem into a continuous one. After the optimization process, we use the optimized parameter to generate malicious vulnerable matrices, which are then used to produce malicious updates.
🧪 Experiments
-
Overall attack performance

-
Different malicious rate

-
Different non-IID degree

🛡️ Ethics and Disclosure
-
This work was conducted with the intent to advance the understanding of vulnerabilities in Federated Ranking Learning (FRL) systems and to promote the development of more robust and secure federated learning frameworks. Our analysis and the proposed Vulnerable Edge Manipulation (VEM) attack are designed strictly for academic research and defensive purposes. All experiments were carried out in controlled environments on publicly available datasets. No real-world systems or user data were compromised or targeted during this study.